模版
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| struct trie
{
int next[26];
int isEnd;
}tree[500005];
int inc;
int insert(string s)
{
int p=0;
for (int i=0;i<s.size();i++)
{
if (tree[p].next[s[i]-97]) p=tree[p].next[s[i]-97];
else
{
inc++;
tree[p].next[s[i]-97]=inc;
p=inc;
}
}
if (tree[p].isEnd) return 1;
else tree[p].isEnd=1;
return 0;
}
int check(string s)
{
int p=0;
for (int i=0;i<s.size();i++)
{
if (!tree[p].next[s[i]-97]) return 0;
p=tree[p].next[s[i]-97];
}
if (tree[p].isEnd) return 1;
return 0;
}
|
解释
字典树,是一种空间换时间的数据结构,又称Trie树、前缀树,是一种树形结构,典型用于统计、排序、和保存大量字符串。利用字符串的公共前缀来减少查询时间,最大限度地减少不需要的字符串比较,查询效率比哈希树高。
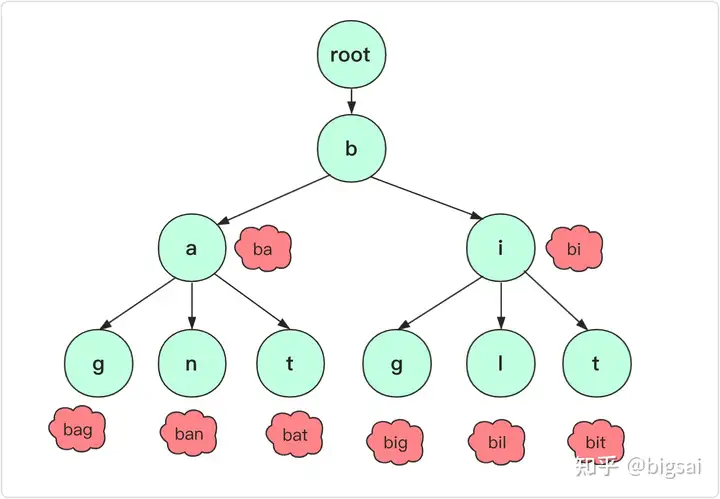
根节点不包含字符,除根节点外每一个节点都只包含一个字符。
从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
定义结构体:该结构体用来存储树的每一个节点,每个节点都包括了指向子节点的指针,以及当前节点是否为单词的结尾。
用数组线性存储树,所以指针记录的是子节点的数组下标值。
inc记录的是当前的数组下标已经分配到多少了,用于分配新的节点。
1
2
3
4
5
6
| struct trie
{
int next[26];
int isEnd;
}tree[500005];
int inc;
|
插入单词:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| int insert(string s)
{
int p=0;
for (int i=0;i<s.size();i++)
{
if (tree[p].next[s[i]-97]) p=tree[p].next[s[i]-97];
else
{
inc++;
tree[p].next[s[i]-97]=inc;
p=inc;
}
}
if (tree[p].isEnd) return 1;
else tree[p].isEnd=1;
return 0;
}
|
检查单词是否存在:
1
2
3
4
5
6
7
8
9
10
11
| int check(string s)
{
int p=0;
for (int i=0;i<s.size();i++)
{
if (!tree[p].next[s[i]-97]) return 0;
p=tree[p].next[s[i]-97];
}
if (tree[p].isEnd) return 1;
return 0;
}
|